Входит в LinguistPro
Reading Room
Двуязычная библиотека — канон иврита с морфологией по тапу.
Целая библиотека, а не пара отрывков
Если редактор LinguistPro — это «принеси любой текст», то Reading Room — «читай канон». Он превращает весь корпус иврита из общественного достояния в двуязычную, направляемую библиотеку чтения, где анализируемо каждое слово — на основе открытой работы проекта Бен-Иегуда (ивритский аналог проекта «Гутенберг»), чей открытый корпус мы каталогизируем, переводим и обогащаем. Он поставляется внутри LinguistPro и разделяет его privacy-first движок, но это самостоятельная учебная поверхность со своим способом входа.
Замысел
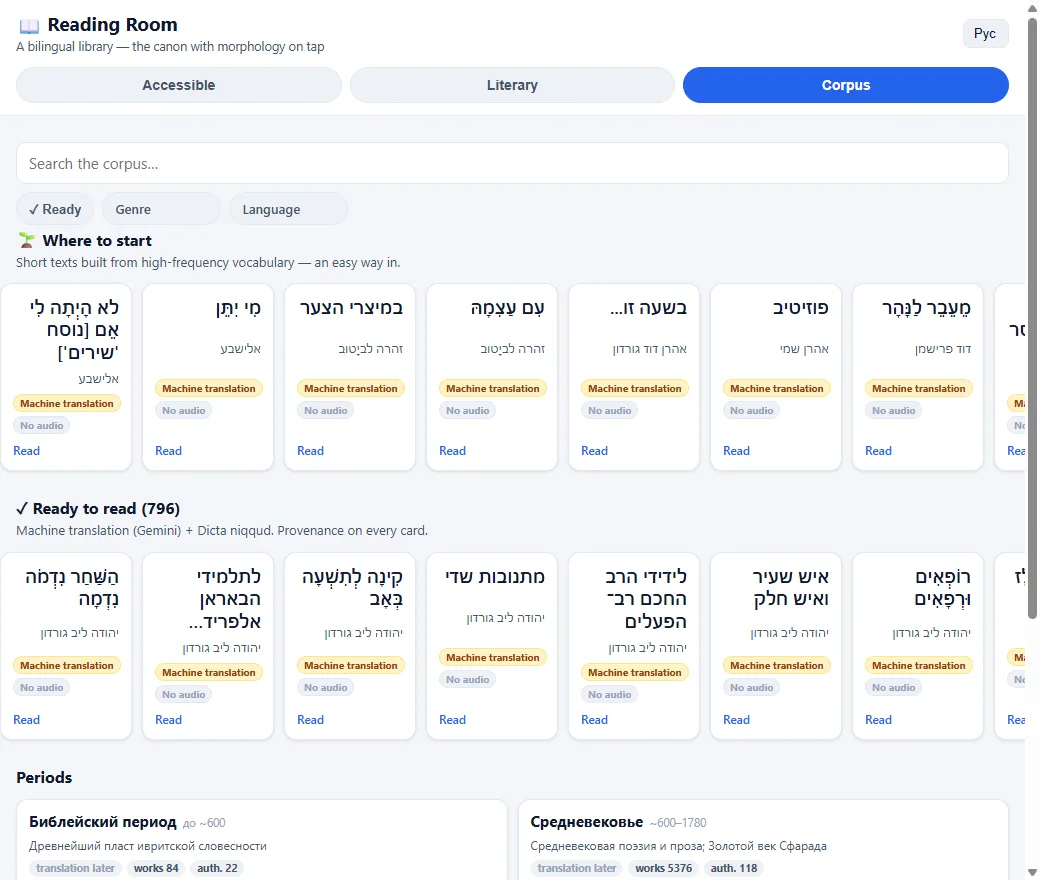
Каталогизировано 26 455 произведений, организованных так, как мыслят об ивритской литературе исследователи: разбивка Период → Автор → Произведение (в паритете с benyehuda.org). Можно двигаться от Библейского слоя через Средневековье (Золотой век Сфарада), Хаскалу, Тхию (возрождение иврита как живого языка), эпоху британского Мандата и Современный канон — поэзия, проза, статьи, мемуары, письма, басни и драма.
Смысл не только в доступе — это градуированный путь. Полка «С чего начать» поднимает короткие тексты, собранные из высокочастотной лексики, — лёгкий вход; персональный движок «следующий для тебя» рекомендует следующий текст чуть выше текущего уровня (принцип i+1 из теории усвоения второго языка), вычисляя всё на устройстве по вашей собственной лексике. Так учащийся может начать с стихотворения в несколько строк и, текст за текстом, дойти до чтения канона в оригинале — с переводом, никудом и полной морфологией всегда в одном тапе.
Честно, served-on-open
796 произведений готовы к чтению уже сегодня: машинно переведены через Gemini и озвучены никудом Dicta, с провенансом на каждой карточке — каждая помечена «машинный перевод» и «озвучки пока нет», и никогда не выдаётся за выверенный вручную канон. Остальная часть корпуса честно помечена «перевод позже» и со временем переходит в «готово» по мере перевода и морфологического обогащения.
Технически это верно privacy-first дизайну LinguistPro. Библиотека каталог-ориентирована и served-on-open: тонкий индекс кешируется заранее, а произведение материализуется в локальное хранилище браузера только при открытии — поэтому корпус из 26 000 работ не нагружает устройство, и ничто из прочитанного его не покидает. Тапните по любому слову для офлайн-морфологии; включите точный «контекстный режим» (Dicta), когда нужна дизамбигуация в конкретном предложении.
Построено на Google Cloud
Gemini переводит корпус на русский (и не только), а Cloud Translation v3 стоит за конвейером нейроперевода — те тяжёлые вычисления, что делают двуязычную библиотеку из 26 тысяч работ возможной для команды-одиночки.