Part of LinguistPro
Reading Room
A bilingual library — the Hebrew canon with morphology on tap.
A whole library, not a handful of passages
Where the LinguistPro editor is "bring any text you like," the Reading Room is "read the canon." It turns the entire public-domain Hebrew corpus into a bilingual, guided reading library where every word is analyzable — built on the open scholarship of Project Ben-Yehuda (the Hebrew-literature counterpart to Project Gutenberg), whose open corpus we catalogue, translate and enrich. It ships inside LinguistPro and shares its privacy-first engine, but it's its own learning surface, with its own way in.
The idea
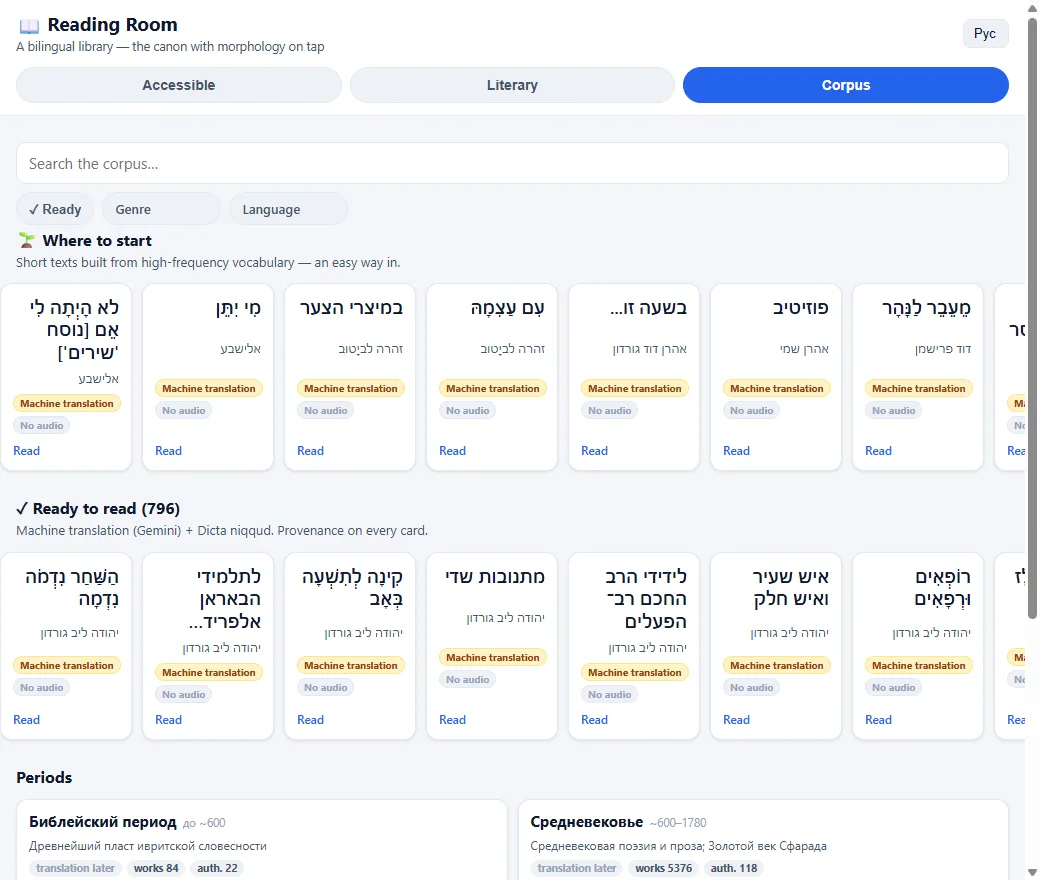
26,455 works are catalogued, organized the way scholars think about Hebrew literature: a Period → Author → Work drill (in parity with benyehuda.org). You can move from the Biblical layer through the Medieval period (the Golden Age of Sepharad), the Haskalah, the Tehiya (the revival of Hebrew as a living language), the British Mandate era, and the Modern canon — across poetry, prose, articles, memoir, letters, fables and drama.
The point isn't just access — it's a graded path. A "Where to start" shelf surfaces short texts built from high-frequency vocabulary, an easy way in; a personalized "next for you" engine recommends the next text just beyond your current level (the i+1 principle from second-language acquisition), computed entirely on-device from your own vocabulary. So a learner can begin with a few-line poem and end, text by text, reading the canon in the original — with translation, niqqud and full morphology always one tap away.
Honest, served on open
796 works are fully ready to read today: machine-translated with Gemini and vocalized with Dicta niqqud, with provenance on every card — each is labelled "machine translation" and "no audio yet", never silently dressed up as the hand-curated canon. The rest of the 26k corpus is honestly marked "translation later" and moves to "ready" over time as the translation and morphological enrichment progress.
Technically it stays true to LinguistPro's privacy-first design. The library is catalogue-driven and served-on-open: a thin index is cached up front, and a work only materializes into your browser-local storage when you open it — so a 26,000-work corpus never weighs down the device, and nothing about what you read leaves it. Tap any word for offline morphological analysis; switch on a precise "context mode" (Dicta) when you want disambiguation in a specific sentence.
Built on Google Cloud
Gemini does the translation of the corpus into Russian (and beyond), and Cloud Translation v3 backs the neural translation pipeline — the heavy compute that makes a 26k-work bilingual library feasible for a solo team.